
Efficient way to troubleshoot on any systems

Working on IT field means also having to deal with daily troubleshooting on more or less complex systems.
I've lost count of the amount of times I asked "Is this the first time"? 😅
Depending on the company in which you work, you could be engaged with an easy chat, email, ticketing systems and so on.
Whatever the engagement channel is, we usually need to start a triage to understand better the problem in order to resolve it as soon as possible.
A part an initial triage to complete the description of the problem if something is missing (ex. date time of when the problem occurs) than we have to start dialing with the problem trying to propose a solution a soon as possible.
In this blog post I want to focus on this last thing that is how to effienctly troubleshoot on any (complex) system.
I voluntarily omitted a lot of details regarding the process of beeing engaged for a problem/outage in order to focus on the alghoritm to apply to effeciently reach the solution.
I summarized it on the following diagram with some explanations.
Basically, the concept is to prioritize the activities which would instead have been made when they had jumped in mind that could be also after 4 hours of trying to troubleshoot.
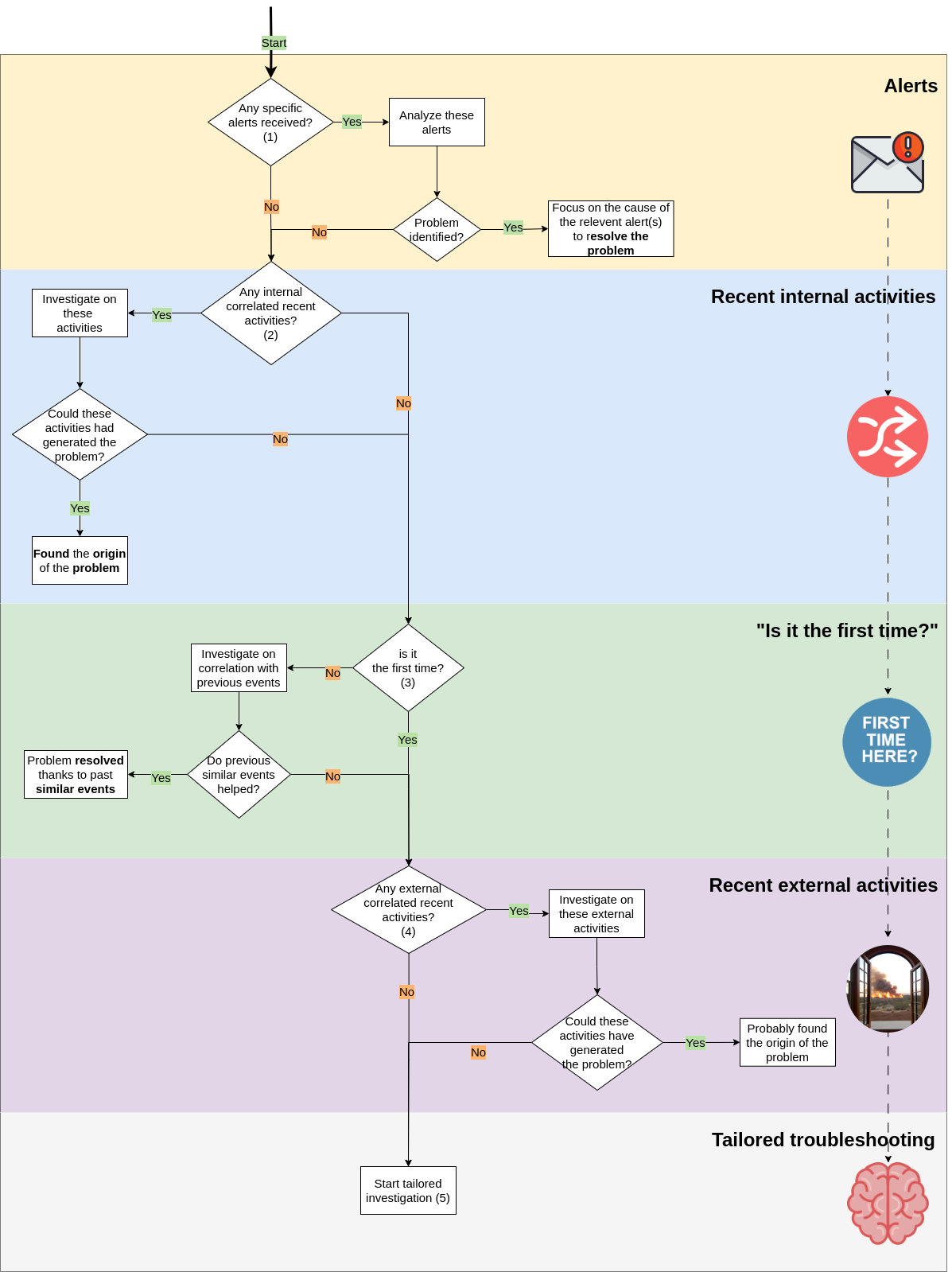
(1) Alerts
Most of complex systems automatically raise alerts when specific events occur.
So we probably have received some kind of alerts (email, messaging apps, etc) which could be related to the encountered problem.
Depending on the type of alert, it could contains the cause or the effect. Pay attention on it while examining received alerts.
I'd like to include here also monitoring systems that are not configured to raise alerts, so check on monitoring available data (ex. graphs) to check if something changed over time.
(2) Recent internal activities
"It can't break if you don't touch it", well it is not always true but in many times yes!
Check out if someone has done recent internal activities.
For internal activities I mean stuff that impacts the area on which the problem raised.
Examples: an application version change, a maintenance activity.
(3) "Is it the first time?"
In many times it is not the first time that this problem occurs, for this reason try to search on documentation/wiki tools for past similar events that could help on resolution.
It's essential to document in a specialized tool and in an organized way all past events that caused outages/problems with descriptions and how it was resolved. It's also essential to take it updated.
(4) Recent external activities
Other times the problem could be caused from the external.
For external we mean the outside area on which the problem occurred.
Modern applications have a lot of external dependencies and due to a potential low fault tolerance, an external failure could cause an outage/problem on our compex systems.
Examples: external FTP servers, external mail server, external integrated services.
(5) Tailored troubleshooting
This is likely the last resort.
Now we basically need to switch on our brain, get deeper into the problem and with technical competence and feels try to understantand the cause.
Unfortunately (of fortunately) I don't have a standard method to do it, experienced people are usually smarter to deal with these kind of activities where no path is already written.




