



Posts
Jul
20

k8s-swiss-knife is born
Kubernetes is famous mainly of its extensibility, kubectl plugins are one of the various proofs.
k8s-swiss-knife the all-in-one-plugin has born!
2 min read
Jan
27
![[k8s] Automatically pull images from GitLab container registry without change the tag](/content/images/size/w750/2024/01/urunner-gitlab.png)
[k8s] Automatically pull images from GitLab container registry without change the tag
Sometimes is very useful in a continuous integration and deployment process to override and push the same image tag (ex. `latest`) to a gitlab registry and then ideally have the same new image up&running from Kubernetes cluster(s).
URunner lighweight tool solves exactly this specific problem.
5 min read
Dec
19

Thanks for all Kubernetes Ingress API, Long life to Gateway API
Ingress API has been frozen.
Yes, you heard well, our lovely Ingress API was officially frozen by Kubernetes itself during October 2023.
7 min read
Oct
31
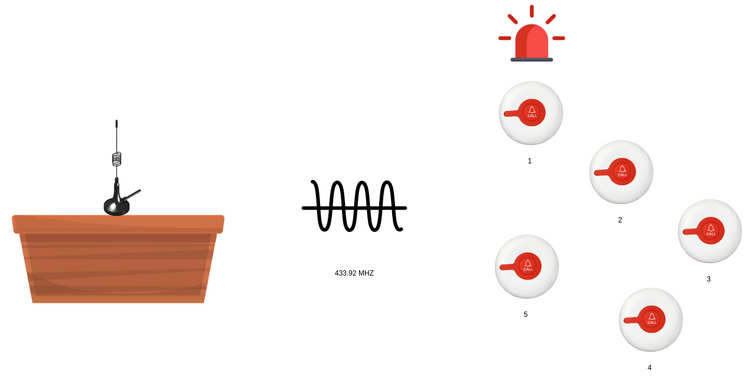
Flipper Zero meets restaurants' pager systems (DDoS attack)
How to use Flipper Zero to better understand what's behind restaurants' pager systems
3 min read
Oct
26
Kubernetes image distribution challenge - thoughts and tests
I studied, compared and tried some solutions (Dragonfly, Uber Kraker, kube-image-keeper,..) to understand how they addressed the above challenge. I then produced a final thought
6 min read
Sep
03

Efficient way to troubleshoot on any systems
There's no greater frustation of trying to troubleshoot on a system for many hours (or days) while the solution was under our nose for all the time.
3 min read
Aug
21
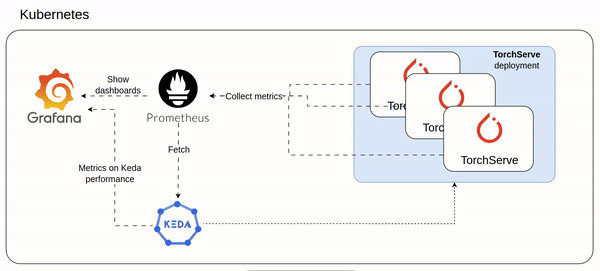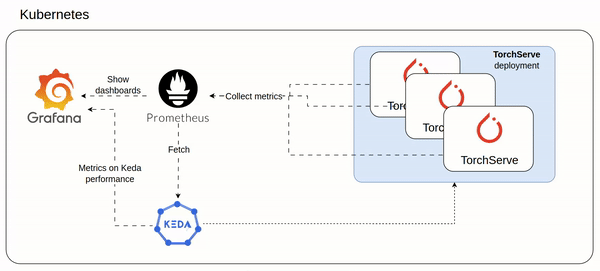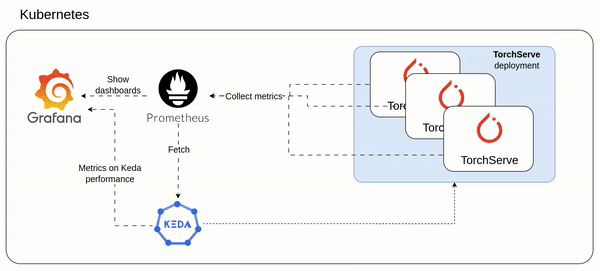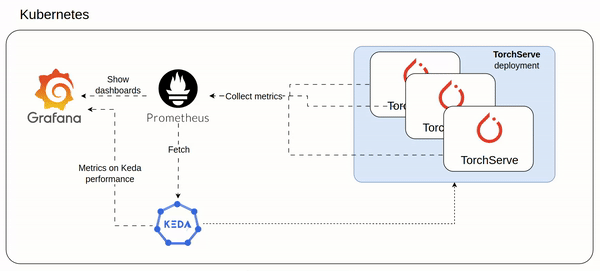
How TorchServe could scale in a Kubernetes environment using KEDA
I almost burned a 7K Euros GPU card (NVIDIA A100 PCIe GPU) to understand how a TorchServe could meet the increasing of ondemand inference requests at scale.
5 min read
Aug
15
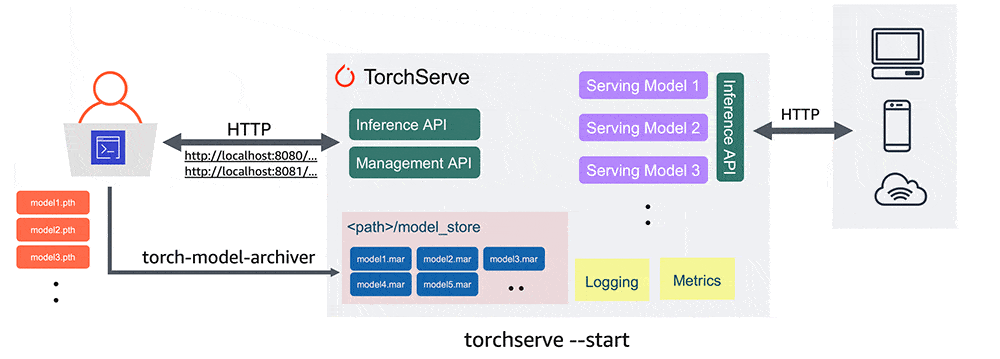
Serve AI models using TorchServe in Kubernetes at scale
In a tipical MLOps pratice, among the various things, we need to serve our AI models to users exposing inference APIs.
I tried a production ready framework (TorchServe) installing it on Azure Kubernetes Service and tested its power to the maximum.
9 min read
Aug
10
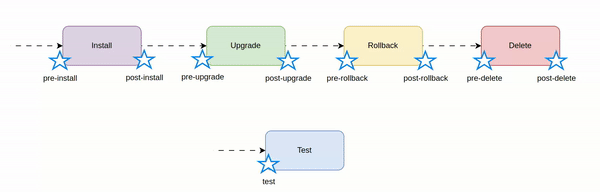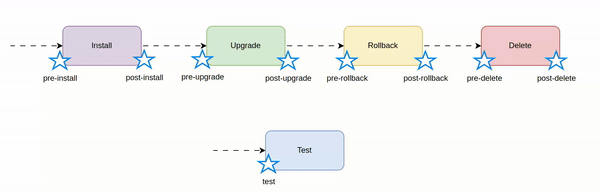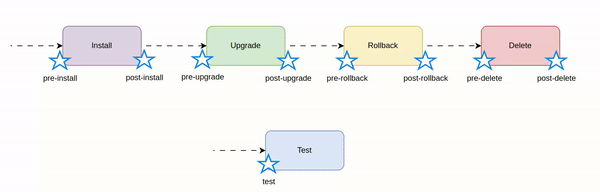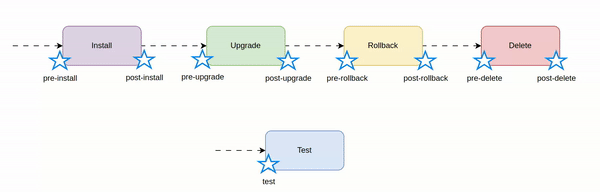
Helm hooks - real use cases
Let's see how Helm hooks work and what are the real use cases.
3 min read
Jul
28

Docker Registry HTTP API V2 demistified once and for all.
Docker Registry HTTP API V2 demistified once and for all.
3 min read