Serve AI models using TorchServe in Kubernetes at scale
Intro
The aim of this blog post was to put together some knowledge I had regarding MLOps and deploy an AI service ready to serve multiple and different AI models (from HuggingFace in this case) in production.
I used TorchServe as a framework in a real Kubernetes as a service scenario (Azure AKS) using Standard_NV6ads_A10_v5 VM with GPU NVIDIA A10.
For doing this I used the Azure free tier which includes 200$ for the first month.
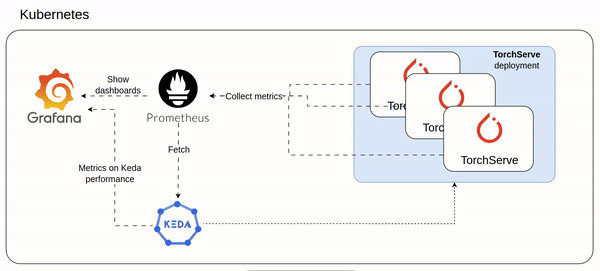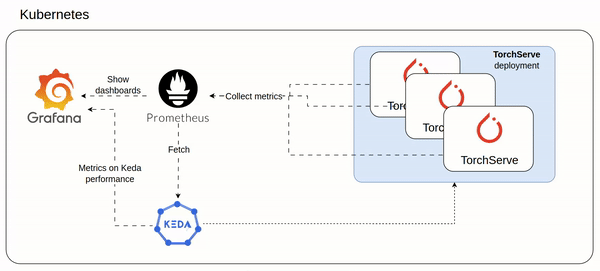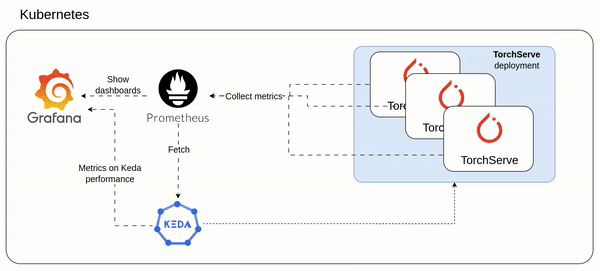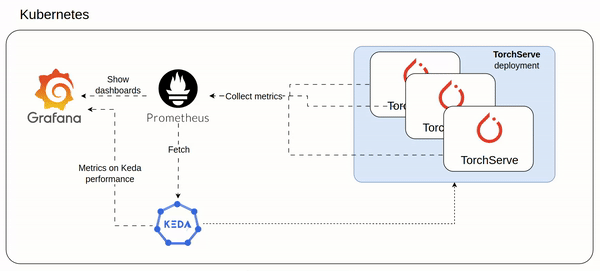
After the setup which involved TorchServe and Prometheus/Grafana stack,
I runned some stress test using JMeter tool to understand how TorchServe reacts and how can be scaled.
Some testes included:
- CPU vs GPU
- Kubernetes Pod scaling
- TorchServe configurations
- workers
- batch size
- Stress tests with JMeter
Finally I reported the original results and some personal thoughts.
Enjoy the reading 😎
One step behind
Two things make me courious and fascinated of MLOps in the past:
- The first one was the Udacity course "Intro to Machine Learning" that I followed in 2017. It opened me a new world.
If you have a basic knowledge of Python I really suggest it, link below 👇👇👇https://learn.udacity.com/courses/ud120
Personally I was fascinated to the included laboratory where you try to find clusters in a real huge and famous database coming from Enron.
What is Enron –> https://en.wikipedia.org/wiki/Enron_scandal - The second one was a project that I did when I was working for my last employer.
It was basically a data extraction project with the aim to speed up the loans processes.
Data were mainly ID cards, passports, etc..
It was 2018 and it was the first time where I needed to setup a sort of MLOps, even if unfortunately with a lot of manual stuff, in order to be deliver new AI models to our users with attention of- time to market
- inference performance
- inference quality
- backward compatiblity / no regression
Recently, I also read the "Introducing MLOps: How to Scale Machine Learning in the Enterprise" (https://www.yuribacciarini.com/books/) and started studying how to deploy multiple AI models in a production environment ready to serve an huge amount of inference requests.
I mainly started from NVIDIA Triton and TorchServe frameworks.
I tried both but I discovered TorchServe more easy to configure and to use so in the following tests I used, as the title say, TorchServe framework.
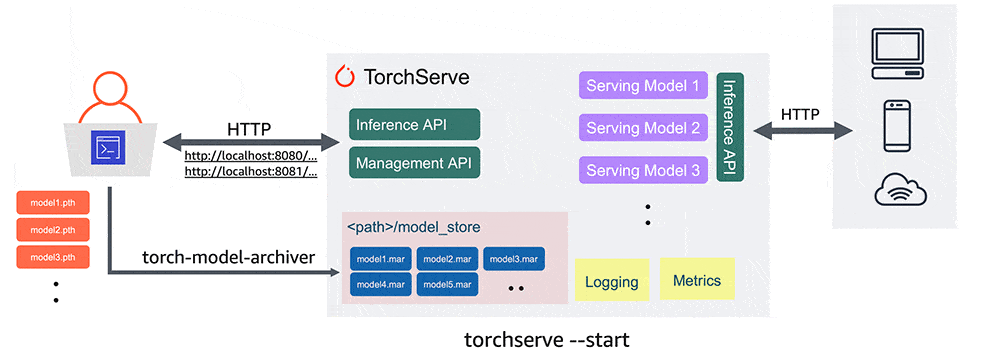
Setup
The exact setup is available on GitHub, I will report here only the core stuff needed to setup a TorchServe container image ready to serve multiple HuggingFace models.
 GitHub
GitHubThe setup allows basically the creation of a container image that contains our production ready server.
Like an hamburger the final docker image is composed by 3 layers:
- nvidia/cuda image
- Torch serve image
- Our custom image (models, Python dependencies, TorchServe configurations, handlers..)
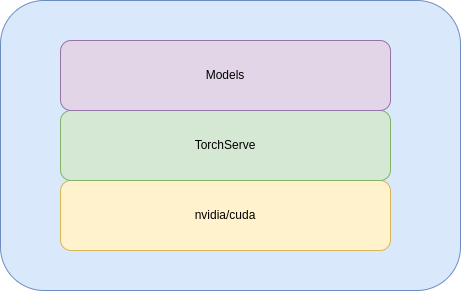
Every new release will change only the upper layer and thanks to Docker layers it will speed up our MLOps
Basically with this image we are ready to deploy our AI server able to serve inference requests.
Let's see how.
1- Download the model from HuggingFace (this is an example of text-classification)
git clone https://huggingface.co/SamLowe/roberta-base-go_emotions2- Write a custom handler
I mainly implemented the inference function (no pre/post processing needed in this case)
What is a TorchServe handler? --> https://pytorch.org/serve/custom_service.html
from abc import ABC
import json
import logging
import os
import subprocess
import torch
from transformers import pipeline
from ts.torch_handler.base_handler import BaseHandler
logger = logging.getLogger(__name__)
class TransformersClassifierHandler(BaseHandler, ABC):
"""
Transformers text classifier handler class. This handler takes a text (string) and
as input and returns the classification text based on the serialized transformers checkpoint.
"""
def __init__(self):
logger.info('__init__ TransformersClassifierHandler')
super(TransformersClassifierHandler, self).__init__()
self.initialized = False
def initialize(self, ctx):
logger.info('initialize TransformersClassifierHandler')
self.manifest = ctx.manifest
properties = ctx.system_properties
model_dir = properties.get("model_dir")
# self.device = torch.device("cuda:" + str(properties.get("gpu_id")) if torch.cuda.is_available() else "cpu")
logger.info("Device: %s", self.device)
print("model_dir: ", model_dir)
device = None
if(torch.cuda.is_available()):
logger.info("Cuda is available. Using GPU")
logger.info("Cuda device count: %s", torch.cuda.device_count())
logger.info("Cuda device name: %s", torch.cuda.get_device_name(0))
logger.info("Cuda current device: %s", torch.cuda.current_device())
device = properties.get("gpu_id")
else:
logger.info("Cuda is not available. Using CPU")
device = -1
self.pipe = pipeline("text-classification", model=model_dir, device=device)
logger.debug('Transformer model from path {0} loaded successfully'.format(model_dir))
self.initialized = True
def preprocess(self, data):
""" Very basic preprocessing code - only tokenizes.
Extend with your own preprocessing steps as needed.
"""
logger.info("Performing preprocessing")
logger.info(data)
logger.info(data[0])
logger.info("Received text: '%s'", data[0]['body'])
return data
def inference(self, inputs):
"""
Predict the class of a text using a trained transformer model.
"""
# NOTE: This makes the assumption that your model expects text to be tokenized
# with "input_ids" and "token_type_ids" - which is true for some popular transformer models, e.g. bert.
# If your transformer model expects different tokenization, adapt this code to suit
# its expected input format.
logger.info("Performing inference")
logger.info(inputs)
prediction = self.pipe(inputs[0]['body'])
logger.info("Model predicted: '%s'", prediction)
return prediction
def postprocess(self, inference_output):
logger.info("Performing postprocessing")
# TODO: Add any needed post-processing of the model predictions here
return [inference_output]
_service = TransformersClassifierHandler()
def handle(data, context):
try:
if not _service.initialized:
_service.initialize(context)
if data is None:
return None
data = _service.preprocess(data)
data = _service.inference(data)
data = _service.postprocess(data)
return data
except Exception as e:
raise ehandler
3- Package the model as .mar for TorchServe usage
How to install torch-model-archiver --> https://github.com/pytorch/serve/blob/master/model-archiver/README.md
The .mar model was introduces by TorchServe to make dfferent AI models more portable.
torch-model-archiver -f --model-name "SamLowe_roberta-base-go_emotions" --version 1.0 \
--serialized-file ../source/roberta-base-go_emotions/pytorch_model.bin \
--extra-files "../source/roberta-base-go_emotions/config.json,../source/roberta-base-go_emotions/merges.txt,../source/roberta-base-go_emotions/special_tokens_map.json,../source/roberta-base-go_emotions/tokenizer_config.json,../source/roberta-base-go_emotions/tokenizer.json,../source/roberta-base-go_emotions/trainer_state.json,../source/roberta-base-go_emotions/vocab.json" \
--handler "../handlers/transformers_classifier_torchserve_handler.py"archive the model as .mar ready for TorchServe
You can iterate 1,2,3 steps for every HuggingFace models you want.
On my repo https://github.com/texano00/TorchServe-Lab you can find a couple of text-classification models and an object-detection model.
4- Build the container image
In order customize the CUDA version you need to build your own TorchServe image.
Start cloning git clone https://github.com/pytorch/serve.git
ARG FROM_IMAGE=pytorch/torchserve:latest-gpu
FROM $FROM_IMAGE
USER root
RUN apt update
RUN apt-get install -y curl
RUN apt-get install -y nano
USER model-server
WORKDIR /home/model-server
# Install python dependencies
ADD docker/requirements.txt requirements.txt
RUN pip install -r requirements.txt
# Include model files
COPY ../model_store /home/model-server/model-store
ENTRYPOINT ["/usr/local/bin/dockerd-entrypoint.sh"]
CMD ["serve"]Dockerfile
Notes:
requirements.txtare needed to install Python libraries needed by our handlersmodel_storecontains our.marmodels previously generated
cd serve/docker
./build_image.sh -t my_base_torchserve:1.0-gpu --gpu --cudaversion <replace-me>
docker build -t my_custom_torchserve:latest-gpu -f docker/Dockerfile --build-arg FROM_IMAGE=my_base_torchserve:1.0-gpu .Build
5- Monitoring stack
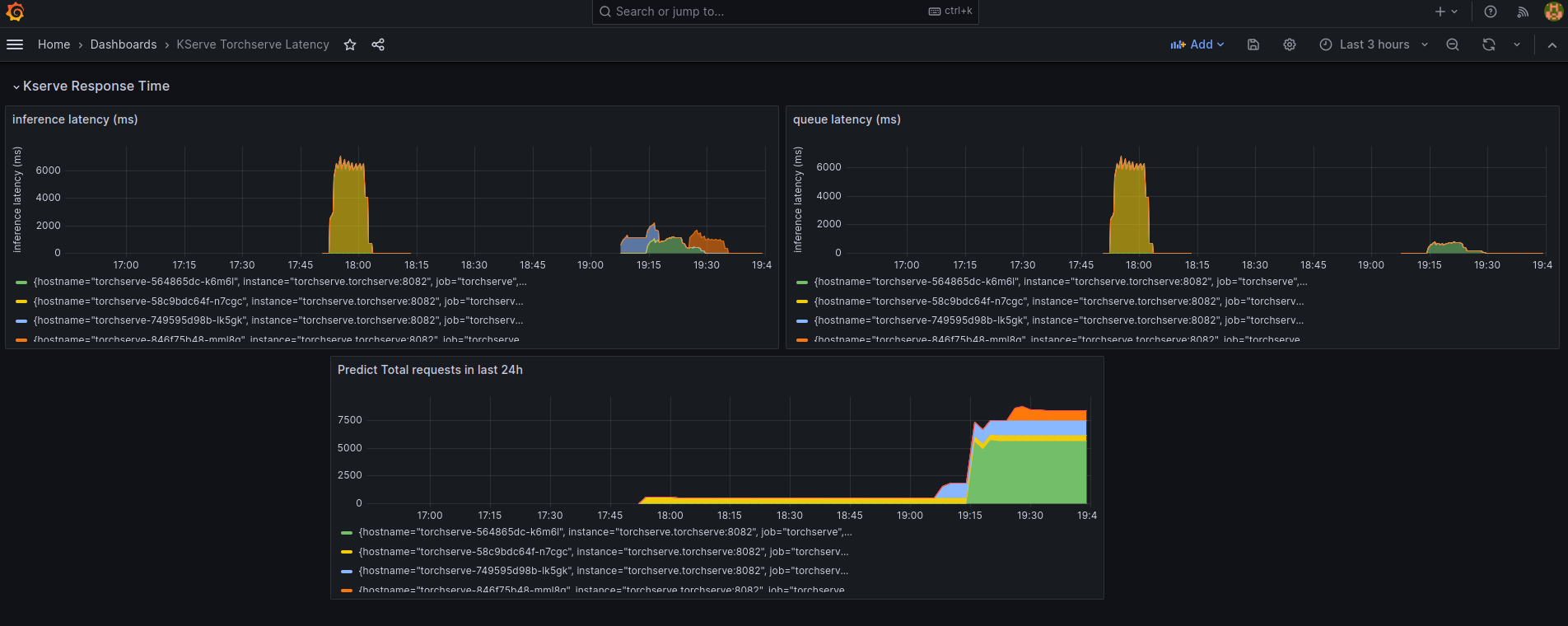
TorchServe can be configured to export prometheus like metrics (see my cofiguration here https://github.com/texano00/TorchServe-Lab/blob/main/kubernetes/torchserve/templates/config.yaml)
In this way we are able to setup a Prometheus/Grafana stack to monitor our TorchServe with custom metrics.
ref. https://github.com/texano00/TorchServe-Lab/tree/main/kubernetes/monitoring-stack
helm upgrade -i monitoring-stack monitoring-stackHelm install monitoring stack
6- Run it!
Now you can run the image in the platform you want.
services:
torchserve:
image: "my_torchserver:latest-gpu"
container_name: torchserve
ports:
- "8080:8080"
- "8081:8081"
- "8082:8082"
volumes:
# - ./model_store:/home/model-server/model-store
- ./config.properties:/home/model-server/config.properties
environment:
TS_CONFIG_FILE: "/home/model-server/config.properties"
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0']
capabilities: [gpu]docker-compose example
Check here for the Kubernetes installation – > https://github.com/texano00/TorchServe-Lab/tree/main/kubernetes/torchserve
Tests
As initially said, I did the following tests on Azure AKS with a single node Standard_NV6ads_A10_v5 VM, GPU NVIDIA A10.
I runned these test from my local machine which is of course outside of Azure environment so network could have impacted the results but, in principle, the results make sense.
I configured the easy tests using JMeter, you can find the setup here https://github.com/texano00/TorchServe-Lab/tree/main/JMeter
I divided the tests in two categories based on the AI model used.
SamLowe_roberta-base-go_emotions
From https://huggingface.co/SamLowe/roberta-base-go_emotions
Type: Text Classification
Best throughput
The best that I was able to do was
51.7 inferences per second
with tolerable degradation (+10ms) on response time.
Details:
- 1 TorchServe worker
- 2 TorchServe pod replicas
- GPU enabled
- 5 parallel users
- Avg response time ~100ms
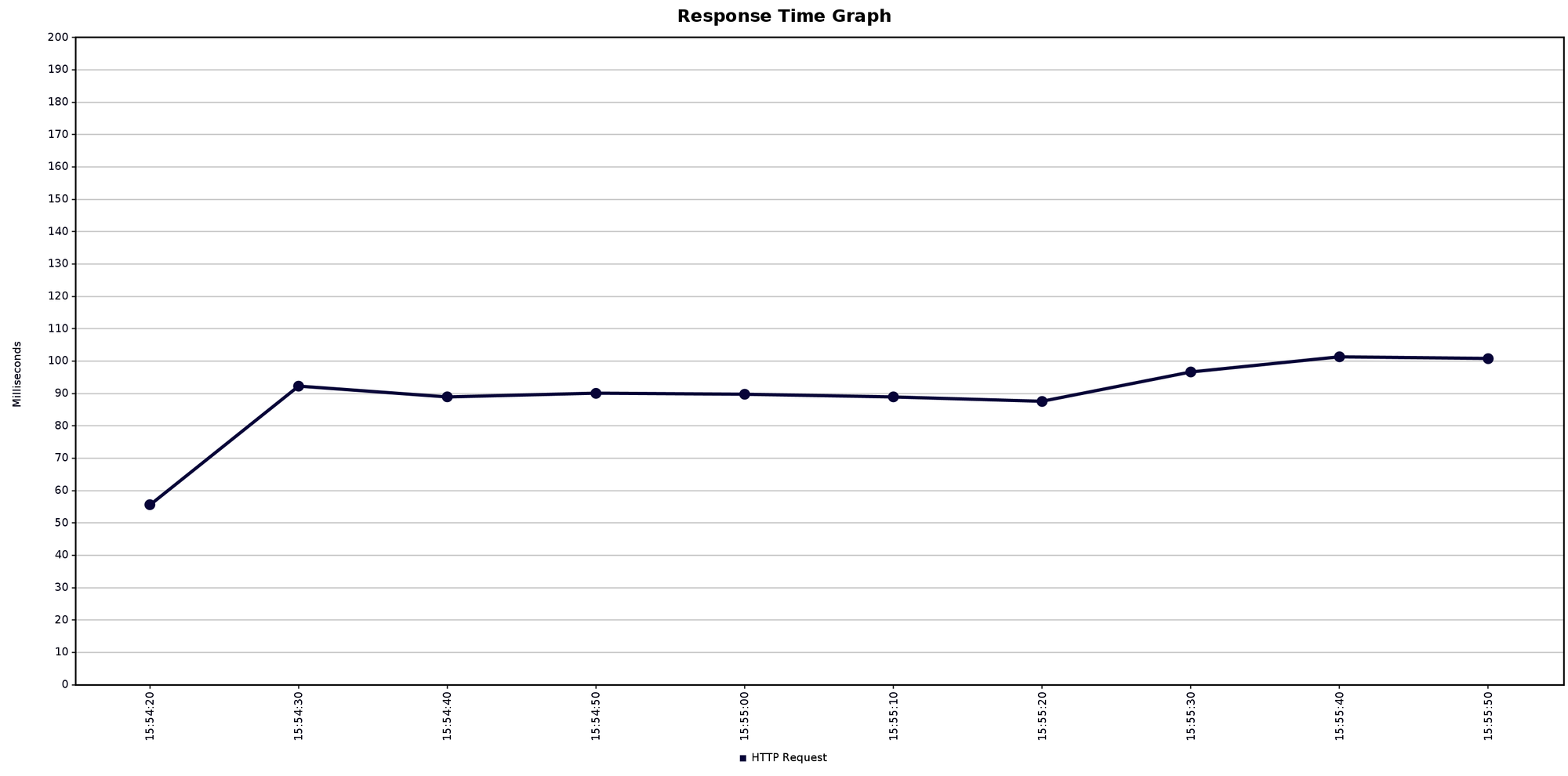
Full results here --> https://github.com/texano00/TorchServe-Lab/tree/main/JMeter/results/aks/Standard_NV6ads_A10_v5/SamLowe_roberta-base-go_emotions/001
CPU vs GPU
Going straight to the conclusions, GPU was of course more performant than CPU probably because this text-classification model is optimized to be runned on GPU.
But since the degradation of performance is not so huge, I'd say that CPU could be a cheaper alternative to GPU (of course with some tuning needed).
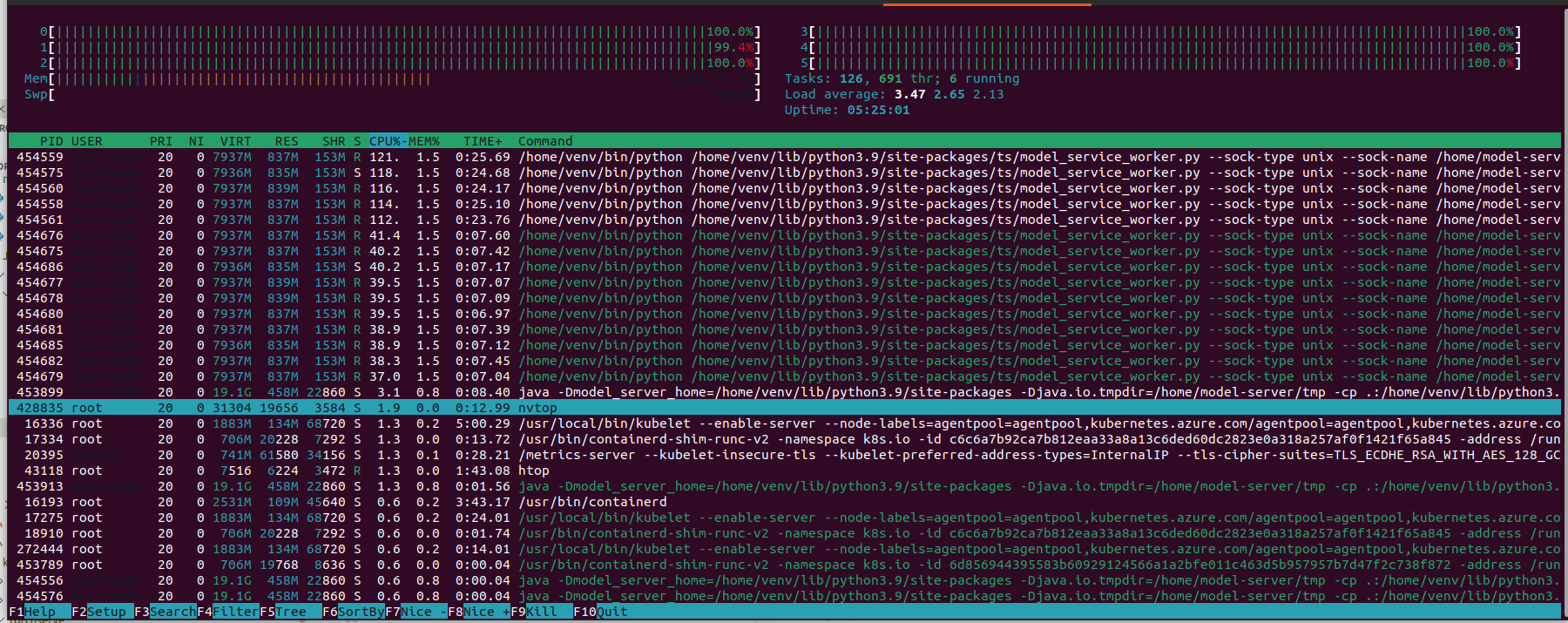
While the memory was not a problem, the CPU usage was a bottleneck.
Instead, with GPU enabled, the CPU was of course almost free and the GPU was not so busy.
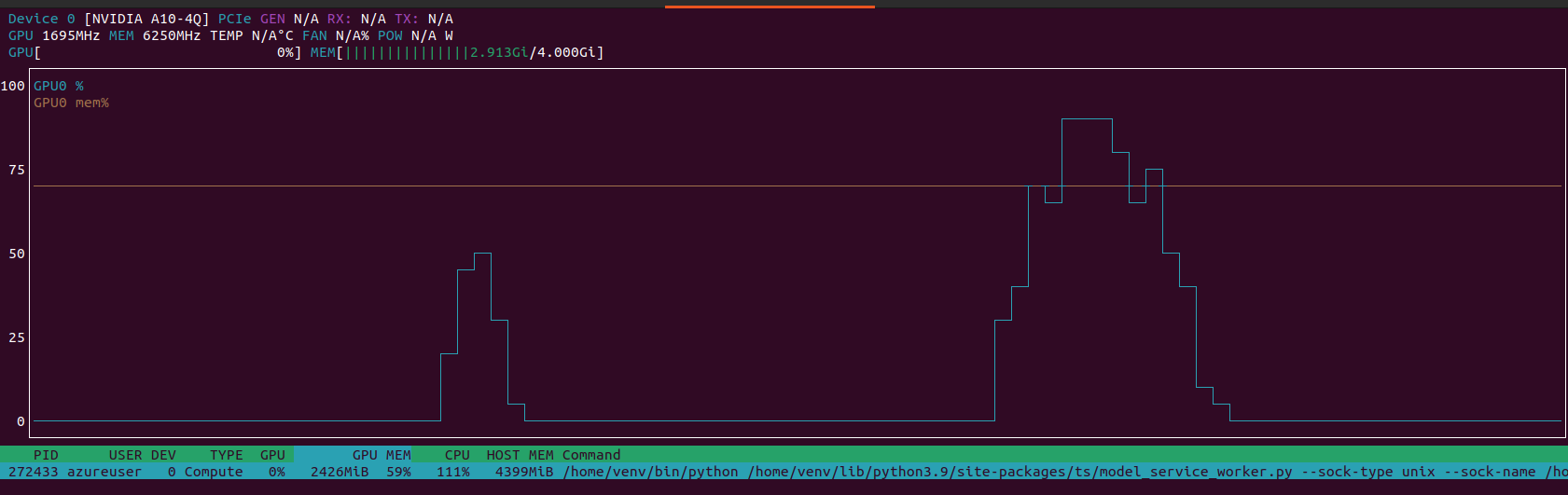
Full result here https://github.com/texano00/TorchServe-Lab/tree/main/JMeter/results/aks/Standard_NV6ads_A10_v5/SamLowe_roberta-base-go_emotions/003
facebook_detr-resnet-50
From: https://huggingface.co/facebook/detr-resnet-50
Type: Object Detection
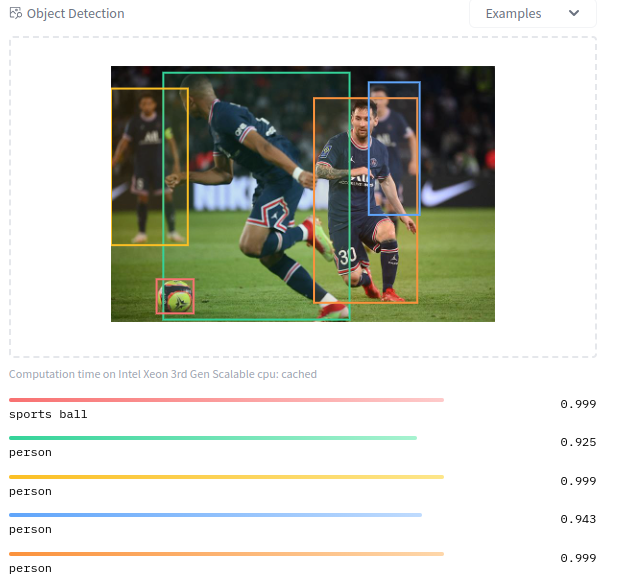
Here the GPU usage was higher than text-classification model.
Best throughput
The best I did here was 4.1 inferences per second.
Details:
- GPU enabled
- 1 TorchServer worker
- 1 pod replica
- 5 parallel users
- avg response time 1200ms
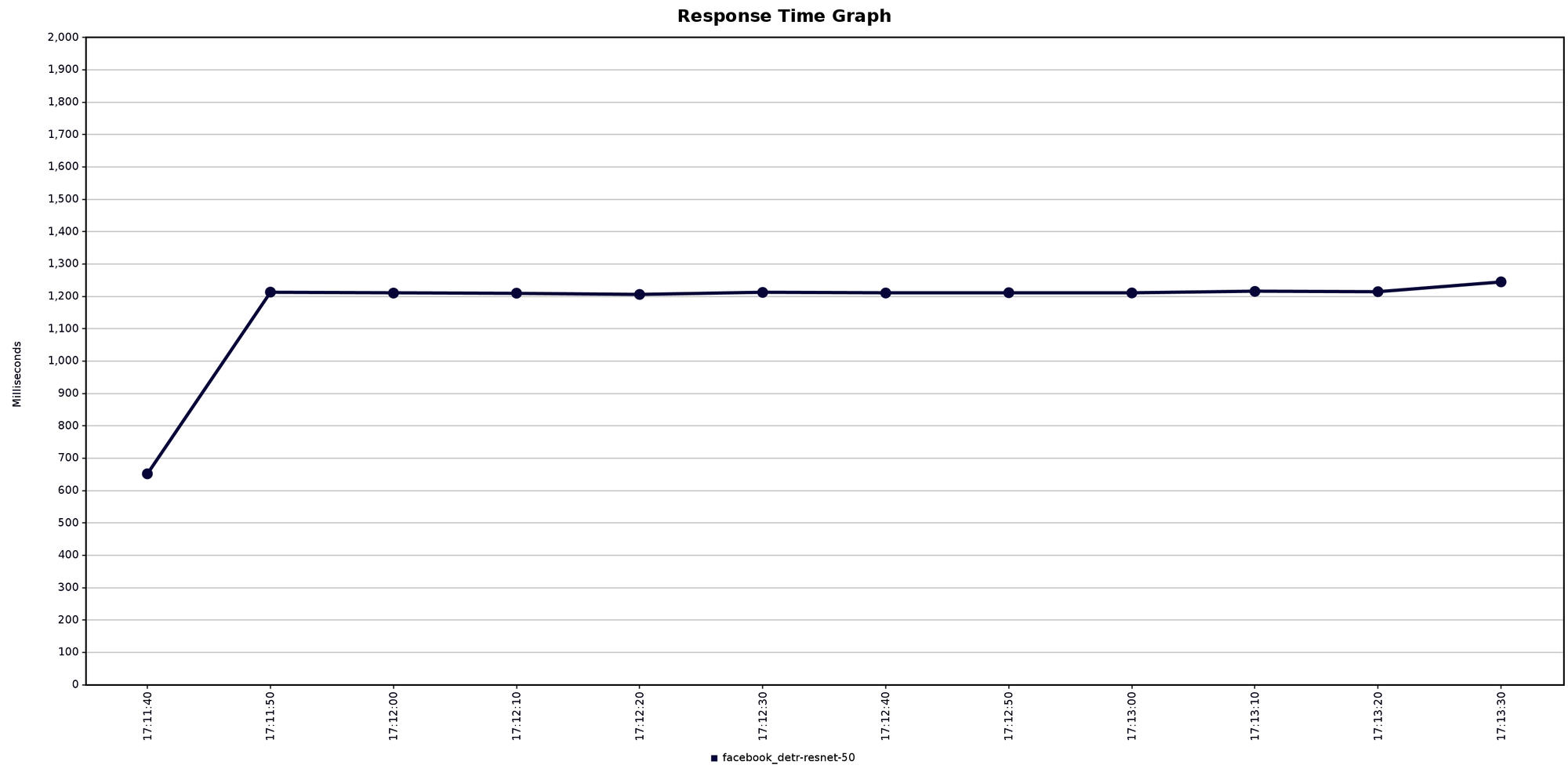
CPU vs GPU
The degradation of using CPU instead GPU was to high in this case so for this object-detection model CPU cannot be used at all.
To give you an idea, with the same setup above, using CPU I obtained:
- throughput 25 inference per minute
- avg response time 11s
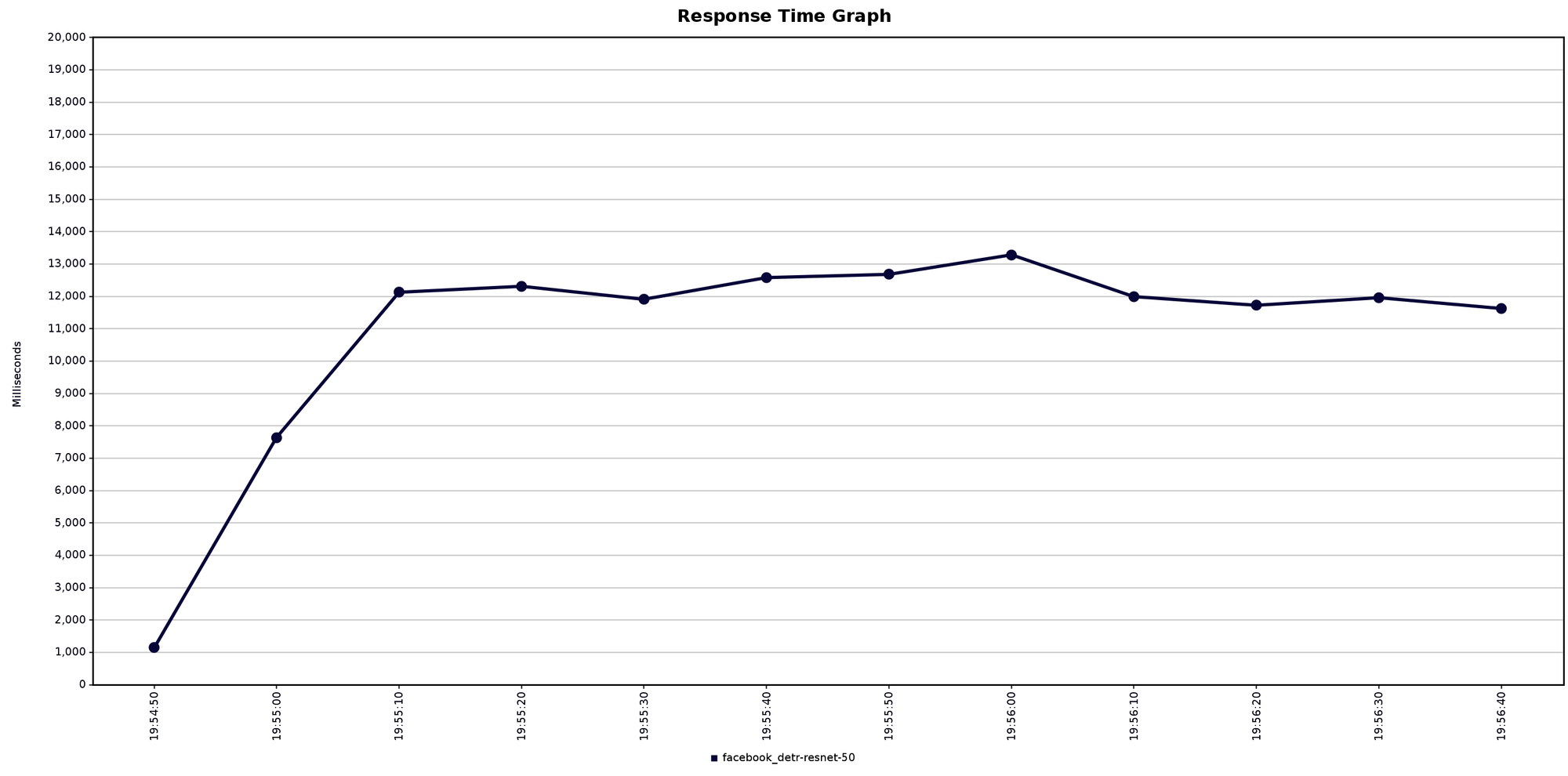
Full tests here https://github.com/texano00/TorchServe-Lab/tree/main/JMeter/results/aks/Standard_NV6ads_A10_v5/facebook_detr-resnet-50
Conclusions
All these tests allowed me to understand better how TorchServe works so I will be able to make a comparison with other frameworks.
In a few hours I was able to
- understand TorchServe
- configure it
- deploy a full working container on a Kubernetes cluster
So I'd say it is a quite easy framework to manage.
The most challanging part was the scaling of the pods and/or TorchServe internal workers due mainly to my limited GPU memory (4GB) but I'd say that the rollout process must be addressed in a dedicated way even if we have more GPU memory.
An other important thing to keep in mind is the huge size of container images.
Just to give an example, my final container image was 10GB.
Even if Docker optimize space using layers, this is an other part to address in order to avoid too high billings.
Finally, thanks to some easy stress tests, I understood how GPU and CPU reacts while using different AI models and GPU is NOT always the answer.
Sometimes CPU could have a similar performance while of course reducing costs.
Here an interesting Microsoft blog post of GPUvsCPU topic https://azure.microsoft.com/es-es/blog/gpus-vs-cpus-for-deployment-of-deep-learning-models/
I haven't documented yet how a GPU Kubernetes cluster could be optimized, as usual before doing it I'd like to make my hands dirty.
Maybe, next topic: MIG (NVIDIA Multi-Instance) vs Time Slicing vs MPS (Multi-Process Service) 🚀🚀🚀

![[k8s] Automatically pull images from GitLab container registry without change the tag](/content/images/size/w750/2024/01/urunner-gitlab.png)