Aug
21
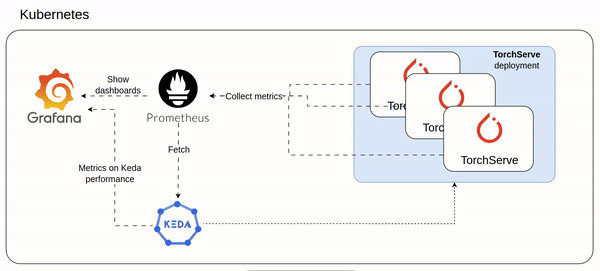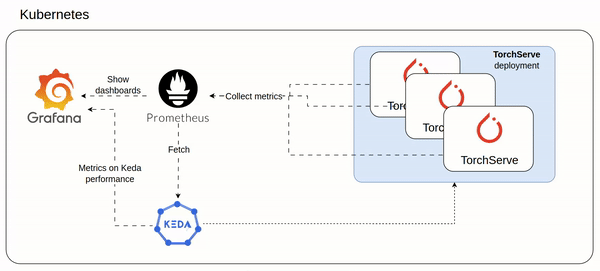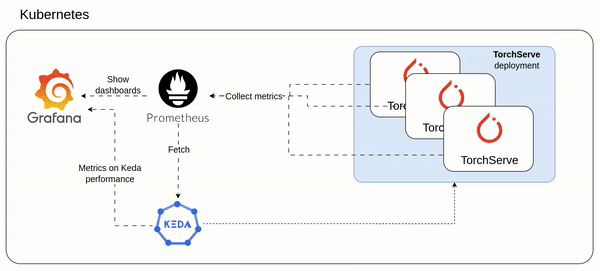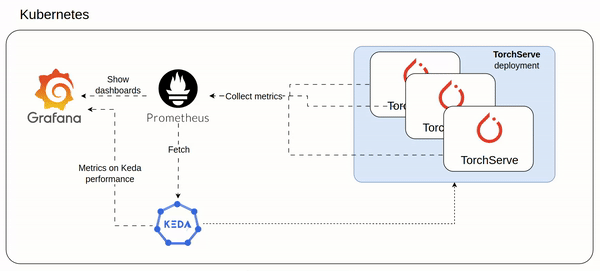
How TorchServe could scale in a Kubernetes environment using KEDA
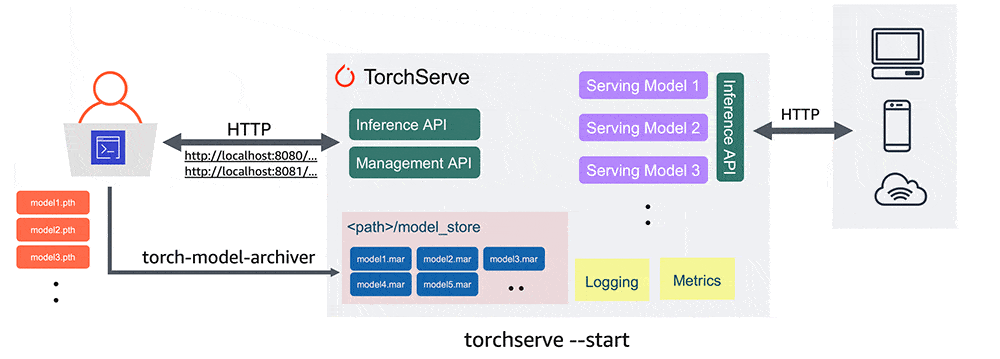
I almost burned a 7K Euros GPU card (NVIDIA A100 PCIe GPU) to understand how a TorchServe could meet the increasing of ondemand inference requests at scale.
5 min read